| Version 11 (modified by , 16 years ago) (diff) |
|---|
MCF Compute Manager
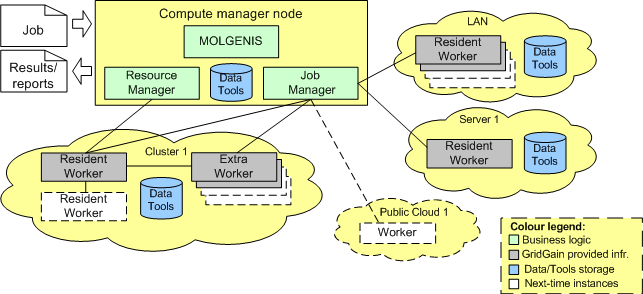
Our computational infrastructure is organised as a ”cloud” and implemented using the GridGain 2.1.1 cloud development platform. The package can be re-used as a stand-alone application or in a combination with the data management. The whole computational logic is located at one ”cloud” node. We call it the Compute Manager node. The rest of the computational ”cloud” is a standard GridGain software deployed in a local network, cluster or server. The topology of our "cloud" is shown in the Figure below.

MCF Compute Manager consists of two modules:
- Job Manager, which distributes jobs across cloud Worker nodes and monitors their executions, and
- Resource Manager, which starts and stops Worker nodes on the cluster.
The Job Manager logic is rather straightforward and can be easily adjusted for use on a specific cluster or server. After a job is received by Job Manager, it is registered in the database and passed to the Worker nodes for execution. There are two different kinds of Worker nodes in the system. These are Resident Workers and Extra Workers. Basically, these nodes are the same standard GridGain? nodes and differ only by name or a cloud segment. Why do we need two different kinds of nodes in the system, if these nodes have the same functionallity? A workflow operation is an execution of a bioinformatics analysis tool, which is invoked from a command line. A usual output is files and a standard command-line output or/and error. The difference between two kinds of Worker nodes is in a way analysis tools are invoked from them. Resident Worker starts a job by sumbitting a shell script to the cluster job scheduler. In contrast to Resident Worker, Extra Worker directly invokes an analysis tool. In this way, the cluster scheduler can be circumvented.
Attachments (1)
- back-end.gif (25.9 KB) - added by 16 years ago.
{kind=link}
Download all attachments as: .zip